Bericht: Seitenindexierung → Nicht indexiert
Schweregrad: mögliche Warnung – Google hat die Seite gesehen, aber sie (noch) nicht in den Index übernommen
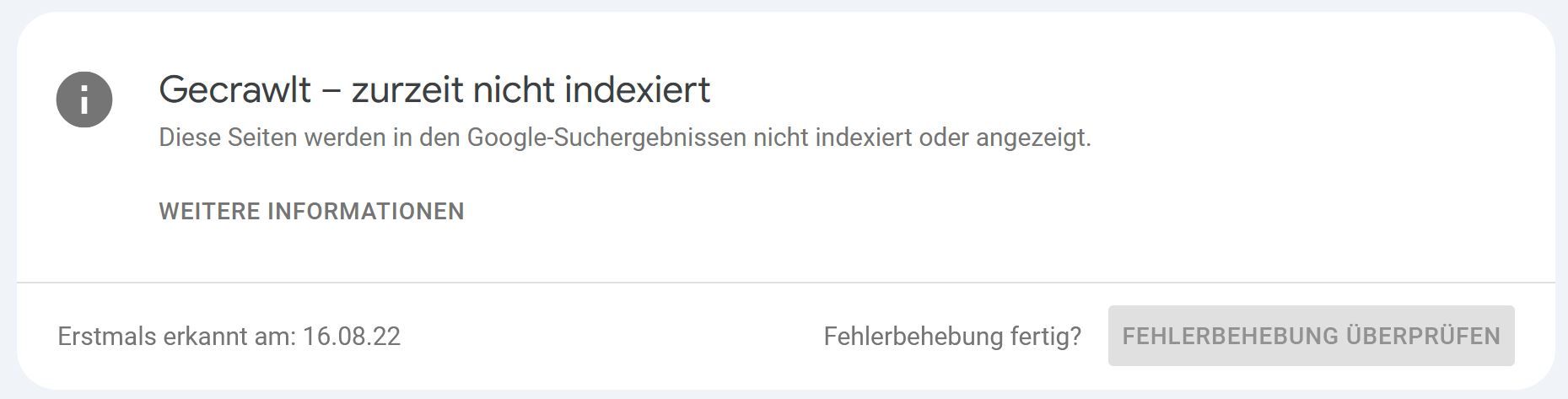
Was bedeutet „Gecrawlt – zurzeit nicht indexiert“?
Die Seite wurde vom Googlebot erfolgreich gecrawlt, landete jedoch nicht im Suchindex. Anders als bei Gefunden – zurzeit nicht indexiert ist hier der Crawl bereits passiert; die URL steckt im Indexing‑Pipeline‑Filter. Gründe sind vielseitig und reichen von Qualitäts‑Signalen bis zu temporären Ressourcen‑Limits.
Kurz: Google hat den Inhalt gesehen, war aber noch nicht überzeugt, dass er (a) einzigartig, (b) relevant oder (c) technisch einwandfrei genug für den Index ist – oder die Seite wartet schlicht in der Warteschlange.
TL;DR (Quick‑Check in 60 Sekunden)
- URL‑Prüfung in der GSC ausführen → Live URL testen.
- Prüfen, ob gerendertes HTML korrekt geladen wird (kein JS‑Fehler, keine Platzhalter).
- Content‑Qualität & Eindeutigkeit beurteilen (Wortanzahl, Mehrwert, Duplicate Check).
- Interne Links & Sitemaps sicherstellen → Seite darf nicht „Waise“ sein.
- Wenn alles stimmt ➜ Geduld: Google indexiert oft innerhalb von Tagen.
Wenn nicht ➜ Content überarbeiten, interne Verlinkung stärken, erneut Indexierung beantragen.
Warum ist das wichtig?
- Traffic‑Verlust: Solange die Seite nicht indexiert ist, erhält sie keinen organischen Traffic.
- Zeit‑Sensitiver Content: News‑Artikel oder Angebote verlieren Wert, wenn sie verspätet indexiert werden.
- Qualitäts‑Signal: Viele URLs mit diesem Status deuten auf grundlegende Content‑ oder Architektur‑Probleme hin.
Häufige Ursachen
Kategorie |
Typische Beispiele |
Maßnahmen |
Content‑Qualität |
Dünner Text (
| Inhalt erweitern, Expertise zeigen, Multimedia einbauen |
Duplicate / Near‑Duplicate |
Starke Ähnlichkeit zu anderen URLs (Produkt‑Varianten) |
Canonical setzen oder konsolidieren |
Interne Verlinkung |
Seite nur über XML‑Sitemap erreichbar, kein Menü‑Link |
Mind. einen Crawl‑tiefen Text‑Link einbauen |
Crawl‑Budget |
Sehr große Sites, viele Parameter‑Seiten |
Parameter ausfiltern, Prioritäten setzen (robots.txt, Sitemap) |
Technische Render‑Probleme |
JS‑Fehler, API‑Blocking, Client‑Side Redirects |
SSR/Hybrid, JS‑Fehler fixen, statische HTML‑Fallback |
Temporäre Backlogs |
Google reduziert Indexing aufgrund von Updates, Ressourcen |
Abwarten – erneute Anfragen vermeiden Spam |
So findest & analysierst du betroffene Seiten
- Search Console → Seitenindexierung → Filter Gecrawlt – zurzeit nicht indexiert → Beispiele exportieren.
- Log‑Dateien: Prüfen, wann Googlebot zuletzt zugegriffen hat und mit welchem Code.
- URL‑Prüfung → Live‑Test: Zeigt gerendertes HTML, Screenshots und JS‑Fehler.
- Site‑Audit‑Tool (Screaming Frog, Sitebulb): Content‑Tiefe, Wortanzahl, Duplicate Percent.
- Copyscape / Siteliner: Duplicate‑Check gegen eigene Domain & Web.
Schritt‑für‑Schritt‑Vorgehen zur Behebung
1 – Content aufwerten
- Füge Mehrwert‑Abschnitte hinzu (FAQ, Beispiele, Studien, Bilder, Videos).
- Optimiere Titel, H‑Tags & Meta‑Description für Klarheit und Relevanz.
2 – Klare Signale senden
- Selbstreferenzielles Canonical‑Tag setzen.
- Interne Links von thematisch starken Seiten einbauen.
- URL in XML‑Sitemap listen.
3 – Technische Checks
- HTTP‑Status = 200, keine langsamen TTFB (> 1 s).
- Render‑Test in GSC → JavaScript & Ressourcen erreichbar.
- Strukturierte Daten validieren (Rich Results Test).
4 – Indexierung anstoßen
- Nach Überarbeitung Indexierung beantragen (nur 1×, Spam vermeiden).
- Optional https://developers.google.com/search/apis/indexing-api/v3 für Job/Live‑Blog‑Posts nutzen (sofern berechtigt).
5 – Monitoring
- Setze in der GSC einen Indexierungs‑Export per API, um Statusänderungen zu tracken.
- Prüfe nach 7–14 Tagen erneut.
Best Practices, um den Status zu vermeiden
- Publisher‑Feeds: Für News‑Sites auf die Indexing API oder Ping‑Sitemaps vertrauen.
- Content‑Plan: Qualität vor Quantität – keine leeren Kategorie‑Seiten online lassen.
- Automatische QA‑Checks: CI‑Pipeline, die Wortanzahl, Canonical‑Tags & HTTP‑Status prüft.
- Server‑Stabilität: Lange Antwortzeiten (> 2 s) können Indexing verzögern.
- Architektur‑Disziplin: Entferne alte, wertlose URLs (410) statt sie hängen zu lassen.
FAQ
„Wie lange dauert es gewöhnlich, bis die Seite doch indexiert wird?“
Zwischen wenigen Stunden und mehreren Wochen. Wenn nach 30 Tagen keine Änderung eintritt, ist Handlungsbedarf angesagt.
„Soll ich die Seite erneut einreichen, wenn sich nichts ändert?“
Nicht häufiger als alle 7 Tage – sonst kann das als Spam gewertet werden.
„Kann Backlink‑Aufbau helfen?“
Hochwertige externe Links signalisieren Relevanz und können die Indexierung beschleunigen.
„Was ist der Unterschied zu Gefunden – zurzeit nicht indexiert?“
Gefunden = noch nicht gecrawlt, Gecrawlt = bereits gecrawlt, wartet auf Indexing‑Entscheidung.
Checkliste
- Content erweitert / optimiert
- Duplicate‑Check bestanden
- Canonical & interne Links gesetzt
- Rendering & Performance ok
- Indexierung beantragt
- Monitoring eingerichtet
Fazit
Der Status „Gecrawlt – zurzeit nicht indexiert“ ist kein Grund zur Panik, sondern ein Hinweis: Google ist sich noch unsicher. Häufig reicht es, die Seite aufzuwerten, interne Signale zu verstärken und geduldig zu warten. Bei systematischen Häufungen solltest du jedoch Content‑Qualität, Architektur und Rendering‑Performance kritisch prüfen.
Weiterlesen:
Warum Seiten noch nicht indexiert werden – Google Hilfe
Quality Rater Guidelines (PDF)

