Duplicate Content, zu Deutsch Doppelte Inhalte, bedeutet, dass identischer Content mehrfach auf verschiedenen URLs aufrufbar ist.
Hierbei wird zwischen drei verschiedenen Arten unterschieden: nach interner, externer und ähnlicher (Near) Duplicate Content.
1. Interner Duplicate Content – Inhalte, die auf einer Website auf verschiedenen URLs vorhanden sind (z. B. wenn die Websites mit http:// und mit https:// einzeln aufrufbar ist).
2. Externer Duplicate Content – Inhalte, die auf verschiedenen Websites aufrufbar sind. Diese Art ist häufig bei Shops zu finden, wenn diese Produktbeschreibungen 1:1 von Herstellern aus dem Internet kopieren.
3. Near Duplicate Content – Inhalte, die einander sehr ähnlich sind (bspw. immer die gleichen Textbausteine, die mehrfach auf unterschiedlichen URLs verwendet werden oder auch Textbausteine, die nur ganz leicht umgeschrieben wurden).
Beispiele für internen Duplicate Content:
➢ Die Website ist mit und ohne www. aufrufbar
➢ URL-Parameter und Sessions-IDs in den URLs
➢ Wiederkehrende, identische Produktbeschreibungen
➢ Paginierungen von Kategorieunterseiten (Seitennummerierungen)
➢ Identische Kategorie und Schlagwörter-Seiten (Übersichtsseiten)
➢ Meta Tags, wie ein identischer Title Tag, werden auf verschiedenen URLs gleichzeitig verwendet
Von Duplicate Content wird nicht gesprochen, wenn ein kurzer Vorspann und eine Überschrift von Beiträgen auf einer Übersichtsseite zum Anteasern verwendet werden. Wörtliche oder ähnliche Zitate, die nur gelegentlich in einem Text vorkommen, stellen ebenso keine Gefahr dar.
Warum stellt Duplicate Content ein Problem dar und wie bewertet Google doppelte Inhalte?
Duplicate Content kann in der Regel zu keiner Abstrafung durch Google führen. Eine Ausnahme stellt der Einsatz von doppelten Inhalten dar, um mit Spam-Methoden (Black Hat SEO) eine Website künstlich in den Suchergebnissen nach vorne zu bekommen.
Solche Spam-Methoden, wie Scraper Sites (geklaute Inhalte) und Spinning Content (automatisiert umgeschriebene Texte), werden manuell abgestraft bei Entdeckung.
Das größte Problem ist für Google das Verständnis, welche URL bei duplizierten Inhalten ranken soll. Gibt es auf verschiedenen URLs die gleichen oder sehr ähnlicher Content, ist es für den Google-Bot schwierig zu entscheiden, welche URL zu welchen Inhalten in den Suchergebnissen gefunden werden soll. Hier entscheidet Google in so einem Fall selbst, und das leider nicht immer richtig. Daher ist es wichtig, DC zu vermeiden und Google ganz klar zu zeigen, welche URL zu welchen Inhalten ranken soll.
Google will außerdem Websites im Index haben, die den Usern einen nennenswerten Mehrwert mit einzigartigem und qualitativ hochwertigem Content bieten. Bei kopierten Texten ist dies nicht der Fall.
Zudem will der Konzern die Crawler nicht unnötig häufig über eine Website schicken – Zeit und andere Ressourcen sollen gespart werden. Bei einer Website mit sehr viel Duplicate Content kommt der Crawler unter Umständen nicht so häufig vorbei wie bei Websites, die frei von dupliziertem oder ähnlichem Content sind. Das Crawl-Budget ist allerdings nur für sehr große Websites (Größenordnung Hunderttausende URLs) relevant; für normale Websites ist es kein Ranking-Faktor.
Ein gutes Video zu diesem Thema findest du von Google selbst:
Google bestraft Duplicate Content im Normalfall nicht.
Stattdessen clustert Google die duplizierten URLs, wählt eine repräsentative kanonische URL aus und filtert die übrigen aus den Suchergebnissen. Dabei werden Ranking-Signale (z. B. Links) auf die ausgewählte URL gebündelt – oder, bei ungesteuerter Duplizierung, auf mehrere URLs aufgeteilt und damit verwässert.
Es geht beim Vermeiden also weniger um „Straffreiheit“ als darum, dass die von dir gewünschte URL die Signale erhält und rankt.
Duplicate Content finden
Es gibt verschiedene Wege, die unterschiedlichen Arten von DC zu erkennen:
- Internen Duplicate Content analysieren
Mit der kostenlosen Google Search Console findest du Hinweise auf doppelte Inhalte. Der frühere Bericht „HTML-Verbesserungen“ wurde Ende März 2019 abgeschaltet; nutze heute den Bericht „Seitenindexierung“ (z. B. Status „Duplikat – vom Nutzer nicht als kanonisch festgelegt“) sowie das URL-Prüfung-Tool.
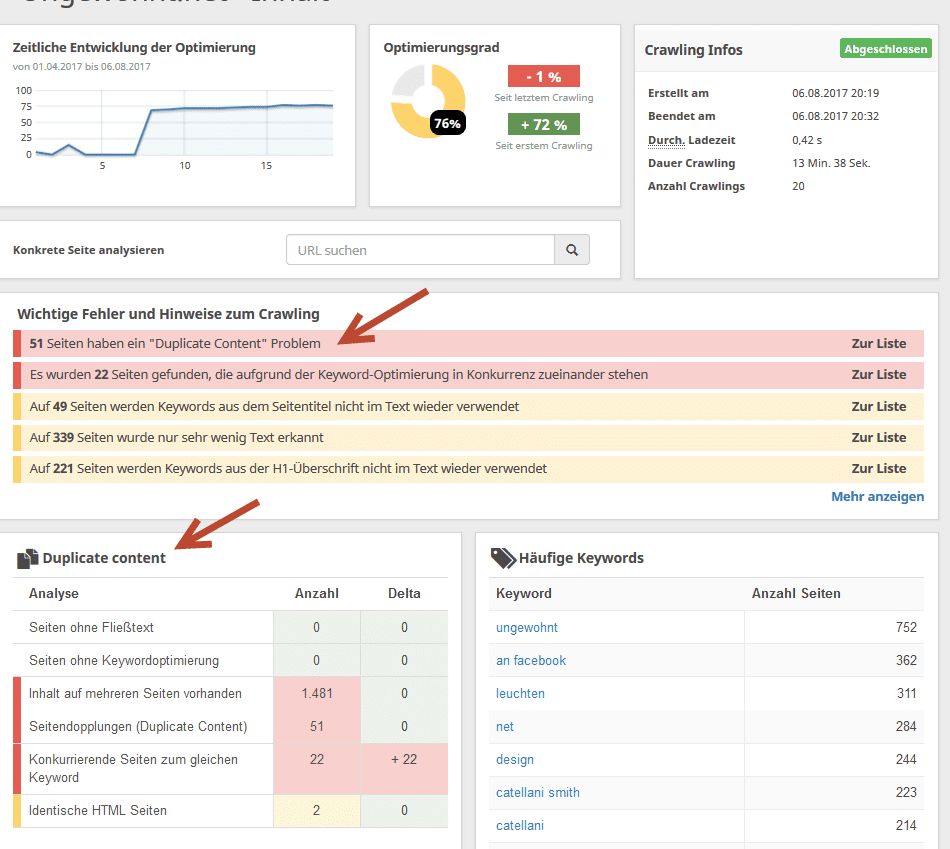
Mit kostenpflichtigen Analyse-Tools wie Seobility und vielen weiteren OnPage-Analyse-Tools kannst du dir Duplicate Content anzeigen lassen.
Auf Siteliner.com kannst du deine Website kostenfrei auf duplizierte Inhalte überprüfen lassen.
- Externen Duplicate Content analysieren
Über die Website Copyscape kannst du dir anzeigen lassen, ob es Kopien zu deiner URL/Website im Netz gibt. Das Analyse-Tool überprüft dabei das Web nach externen Quellen, die ähnliche oder identische Übereinstimmungen zu deiner Anfrage haben.
- Über die Google-Suche (externer wie auch interner DC)
Über die Suche von Google können sowohl interner wie auch externer Content gefunden werden. Gib dazu eine Textpassage ein, von der du denkst, dass diese doppelt auf deiner oder anderen Website vorhanden ist. Setze die Passage des Textes mit Anführungszeichen („“) in die Suche ein – bekommst du jetzt mehrfache Ergebnisse angezeigt, solltest du überprüfen, ob diese Ergebnisse identische Inhalte vorweisen.
- Near Duplicate analysieren
Mit den bereits genannten Tools wie Seobility lassen sich auch häufig Texte erkennen, die sehr ähnlich zueinander sind. Unter dem Punkt „Inhalt“ -> „Konkurrierende Seiten zum gleichen Keyword“ lassen sich oft Seiten finden, die near DC haben. Auch Siteliner.com zeigt dir URLs auf deiner Website an, die einander ähneln. Bei Seobility.net findest du über „Inhalt“ -> „Duplicate Content“ alle Seiten aufgelistet, die aufgrund der Keyword-Optimierung in Konkurrenz zueinanderstehen.

Lösungen für Duplicate Content
Sollte bei der Analyse herauskommen, dass du DC-Probleme auf deiner Website hast, solltest du handeln und die Probleme beheben. Im Folgenden zeige ich einige Möglichkeiten auf, DC zu beheben.
✔ Weiterleitungen für die Domain und einzelne URLs
Eine Domain sollte entweder über www. oder ohne erreichbar sein: Nehmen wir an, dass deine Website nur über www. erreichbar sein soll, musst du einen entsprechenden Weiterleitungsbefehl in die .htaccess-Datei eintragen.
Ferner sollte deine Website, falls du über dies verfügst, nur über https:// aufgerufen werden können.
Verfügst du über alte URLs, die über identische Inhalte im Vergleich zu deiner neuen Website verfügen, solltest du diese entsprechend mit einer 301-Weiterleitung (Redirect) umleiten. Diesen Befehl trägst du ebenfalls in die .htaccess-Datei deiner Seite ein. Ein Beispiel:
RewriteRule ^alte-url/?$ /neue-url/ [R=301,L]Auf der Website: http://www.htaccessredirect.de/ gibt es weitere Tipps, wie man die .htaccess mit Weiterleitungen konfigurieren kann.
✔ Seiten auf „noindex“ setzen
Über den Eintrag eines Meta-Tags mit „noindex,follow“ gibst du Google die Anweisung, die Seite nicht in den Suchergebnissen aufzunehmen. Damit lassen sich doppelte Inhalte schnell beheben. Bedenke allerdings, dass diese Seiten weiterhin von Google überprüft werden. Wird eine Seite gar nicht mehr benötigt, ist zu überlegen, ob es nicht sinnvoll wäre, sie zu löschen und/oder per 301-Redirect umzuleiten.
Faustregel zur Abgrenzung: noindex eignet sich, wenn eine Seite erreichbar bleiben, aber nicht ranken soll; ein 301-Redirect ist richtig, wenn die Seite dauerhaft ersetzt oder aufgelöst wird.
✔ Canocial Tags
Mithilfe des Canonical Tags kannst du anzeigen, welche URL das Original ist und welche Kopie von Google ignoriert werden soll. Ein Beispiel im <head>:
<link rel="canonical" href="https://www.beispiel.de/original/" />
✔ Indexierung verhindern, Seite aber crawlbar lassen
<link meta name="robots" content="noindex,follow" />
✔ Mehrsprachige Websites
Häufig kann es zu Problemen mit Duplicate Content auf mehrsprachigen Websites kommen. Hier ist die hreflang-Annotation das richtige Mittel.
Bei länder- oder sprachspezifischen Versionen derselben Seite sagt hreflang Google, welche Sprach- bzw. Länderversion welcher Zielgruppe ausgespielt werden soll, z. B.:
<link rel="alternate" hreflang="de-DE" href="https://www.beispiel.de/" />
<link rel="alternate" hreflang="en-US" href="https://www.beispiel.com/" />
Wichtig: hreflang ergänzt den Canonical und ersetzt ihn nicht – beide Sprachversionen bleiben indexierbar.
✔ Kopierte Inhalte entfernen oder komplett neu- / umschreiben
Geklaute Produktbeschreibungen und doppelt verwendete Texte sollten von einer Website schnell verschwinden. Google will einzigartige Texte auf deiner Website sehen und sieht kopierte Inhalte nicht gerade als Zeichen von hoher Qualität an.
Lösungen für Duplicate Content, die nicht empfohlen werden
⚡ Das Ausschließen des Google-Crawlers über die robots.txt-Datei, um DC zu beheben, wird nicht empfohlen, da das Ausschließen nicht zwangsweise dazu führt, dass die URL aus dem Index von Google entfernt wird. So bleibt der Duplicate Content bestehen, nur kann Google diesen nicht wieder erneut crawlen.
⚡ Der Bericht „Entfernen“ (Tool zum vorübergehenden Entfernen) in der Search Console sollte ebenfalls nicht zum Beheben doppelter Inhalte verwendet werden, da URLs hier nur kurzzeitig aus dem Index ausgeschlossen und danach wahrscheinlich wieder aufgenommen werden.
Tipps von Google zur Vermeidung
Auf https://support.google.com/webmasters/answer/66359?hl=de gibt es viele Tipps von Google selbst zur Vermeidung und Behebung:
- 301-Weiterleitungen verwenden
- Immer die gleichen URL-Strukturen verwenden
- Die Search Console nutzen, um sich bspw. auf bestimmte Sprachversionen festzulegen
- Wiederkehrende Textbausteine vermeiden
- Ähnlichen Content und kopierte Inhalte nicht veröffentlichen oder auf noindex setzen
Zusammenfassung
Einzigartige Text auf einer Website sind für Google ein Zeichen von hoher Qualität und bieten dem Leser einen Mehrwert. Setze daher alles daran, DC-Probleme zu finden und zu beheben. Mit diversen SEO-Tools kannst du die Übeltäter schnell finden und entsprechend reagieren. Lösche entweder Duplicate Content oder setze doppelte Inhalte auf „noindex,follow“.
Sollte eine andere Website dein Content 1:1 kopieren, solltest du den Webmaster kontaktieren und darauf hinweisen und zur Not sogar mit rechtlichen Schritten drohen. Die eigenen Inhalte auf deiner Website sind dein höchstes Gut und sollten dementsprechend gepflegt werden.
Quellen
- Google, Die „Duplicate Content-Penalty“ – entmystifiziert! https://developers.google.com/search/blog/2008/09/demystifying-duplicate-content-penalty?hl=de

