SEO Grundlagen & Strategie
Die Wissenschaft hinter den Suchmaschinen: Information Retrieval erklärt


Wie Suchmaschinen arbeiten, habe ich im letzten Blogartikel dargestellt. Doch wie genau funktioniert das Finden von bestimmten Informationen in den unzähligen Mengen an Daten bei einer Suchmaschine genau, damit blitzschnell relevante Suchergebnisse für den Nutzer ausgespielt werden können?
Genau hier kommt „Information Retrieval (der Abruf von Informationen)“ zum Einsatz. Das ist sozusagen die Wissenschaft hinter den Suchmaschinen.
Was das genau ist und welche Modelle es gibt, zeige ich in diesem Artikel.
Was ist Information Retrieval und warum ist das für SEO relevant?
Information Retrieval ist eine Disziplin aus dem Bereich der Informatik und hat das Finden von bestimmten Informationen aus großen, ungefilterten Datenmengen zur Aufgabe. Genau diese Aufgabe gibt es bei einer Suchmaschine für die Bereiche Crawler, Indexer und Searcher.
Der Searcher muss auf eine Suchanfrage die bestmöglichen Suchergebnisse für den Nutzer ausspielen. Dazu greift er auf die aufbereiteten Daten aus dem Index zurück. Der Indexer muss die Rohdaten aus dem Local Store des Crawlers sehr gut aufbereiten und sortieren. Dabei gibt es verschiedene Modelle und Maßnahmen, wie solche Daten aufbereitet werden. Doch fangen wir zunächst einmal damit an, auf das Problem der Unstrukturiertheit von Daten einzugehen:
Probleme einer Suchmaschine
Es ist unmöglich für eine Suchmaschine, aus einer großen, unsortierten Datenmenge in wenigen Millisekunden die richtigen bzw. für den Nutzer relevanten Suchergebnisse auszuspielen. Je schneller eine Suchmaschine ihre Ergebnisse ausspielt, desto zufriedener sind auch ihre Nutzer – aber natürlich nur, wenn die ausgespielten Ergebnisse relevant und passend zur Suchanfrage sind. Damit die Suchmaschine alle gespeicherten Daten schnell abrufen und relevante Ergebnisse anzeigen kann, müssen diese Daten entsprechend aufbereitet und sortiert werden.
Ein weiteres Problem für Suchmaschinen bilden ungenaue Suchanfragen vonseiten der Nutzer selbst. Auch aufgrund von ungenauen Anfragen kann der Nutzer unzureichende Informationen erhalten. Das System der Query Modification verändert die Suchanfrage deshalb selbstständig, um relevante Suchergebnisse anzeigen zu können. Hier wird u. a. eine Stoppwortelimierung eingesetzt und so wird z. B. das Wort „und“ bei einer Suchanfrage außer Acht gelassen.
Weitere Query Modifications:
- Mithilfe des Thesaurus werden Synonyme und verwandte Begriffe für die Suchanfrage abgeleitet.
- Durch die Mehrwortgruppenidentifizierung wird die Gruppierungen von Wörtern als solche erkannt.
- Mit der Grund- und Stammformreduzierung werden Wörter auf ihre Wortstämme reduziert. Flexionsformen eines Begriffs (z. B. Hut und Hutes) würden sonst nicht richtig angezeigt werden.
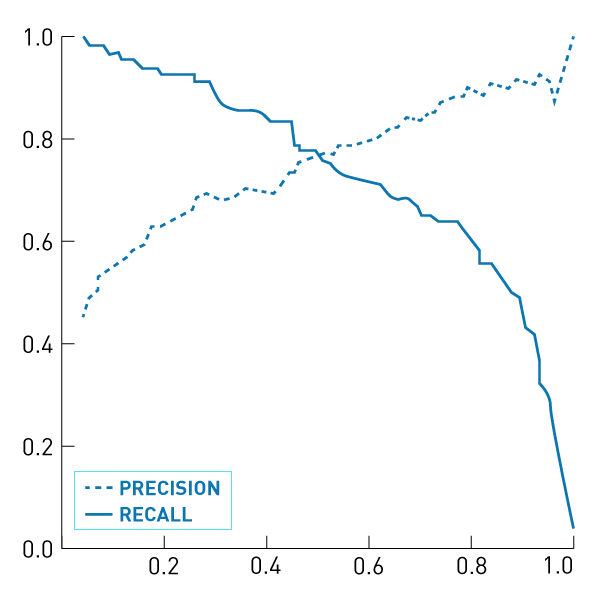
Recall & Precision
Wie effektiv ein Information-Retrieval-System ist, wird mit Hilfe der beiden Faktoren Recall (Trefferquote) und Precision (Genauigkeit), die als Quotienten (siehe Grafik unten) dargestellt werden, berechnet.
- Recall beschreibt die Vollständigkeit (den Abdeckungsgrad) der Suchergebnisse. Dabei wird gemessen, wie viele relevante Dokumente im Verhältnis zu allen relevanten Dokumenten, die in der Datenmenge gespeichert sind, angezeigt werden.
- Precision beschreibt die Genauigkeit der Suchergebnisse, also die Anzahl an relevanten gefundenen Dokumenten im Verhältnis zu den gesamten erhaltenen Suchergebnissen zu einer Anfrage.
Die beiden Quotienten berechnen also die Vollständigkeit und Genauigkeit der Suchergebnisse und können in einem Achsendiagramm dargestellt werden. Beide Werte liegen zwischen 0 und 1. Eine 1 wäre das perfekte Ergebnis. Dabei würden alle relevanten Dokumente zu einer Anfrage angezeigt werden und darunter würde sich gleichzeitig kein unrelevantes Dokument befinden. In der Praxis ist dieses Ergebnis aber nicht erreichbar. Wer die Genauigkeit (Precision) der relevanten Suchergebnisse erhöht, verringert damit ihre Vollständigkeit (Recall).
Schon gewusst?
Das Thema Information Retrieval ist übrigens älter als das Internet. Schon 1945 beschrieb der US-Wissenschaftler Vannevar Bush in seinem Aufsatz „As We May Think“, wie Menschen ihr Wissen besser zugänglich machen könnten. In den 1950er-Jahren entwickelte Hans Peter Luhn Methoden wie die automatische Indexierung und Volltextverarbeitung – Grundlagen, die bis heute in Suchmaschinen stecken.
Weitere Herausforderungen beim Ausspielen von Suchergebnissen werden im Folgenden aufgezeigt:
Relevanz, Pertinenz und Nützlichkeit
Ein Suchergebnis kann relevant sein, es muss aber nicht pertinent sein. Die Pertinenz bezieht sich auf die subjektive Sicht des Nutzers. Wenn ein User den Text des relevanten Suchergebnisses z. B. bereits kennt, ist dieses nicht pertinent für ihn. Ein Suchergebnis ist erst dann nützlich für den User, wenn dieser daraus neues Wissen gewinnt, das er in der Praxis nutzen kann.
Google & Co. haben also die Aufgabe, relevante Suchergebnisse auszuspielen, die dem User nützlich und zudem nicht bekannt (pertinent) sind und die ihm etwas Neues aufzeigen.
Mit Hilfe sogenannter Retrieval-Modelle versuchen Suchmaschinen die bestmöglichen Suchergebnisse für die Suchanfragen ihrer User anzuzeigen.
Retrieval-Modelle und Rankingfaktoren
Beim Information Retrieval gibt es verschiedene Modelle, die dabei helfen sollen, passende Suchergebnissen aus einer (großen, unsortierten) Datenmenge auszuspielen. Diese Modelle schließen sich dabei nicht aus, sondern können miteinander verknüpft werden. Hier ein Auszug häufiger Modelle:
- Das Boolesche Modell (mengentheoretisches Modell): Hier werden Zusammenhänge durch Mengenoperationen (UND, ODER und NICHT) ermittelt.
- Das Vektorraummodell und das probabilistische Modell sind Modelle, die auf der Textstatistik beruhen (WDF*IDF).
- Zu den Linktopologischen Modellen gehört u. a. der berühmte PageRank. Hier werden die Verlinkungen der Dokumente miteinander berücksichtigt.
Diese Modelle zeigen, mit welchen Rankingfaktoren eine moderne Suchmaschine arbeitet. Natürlich ist die genaue Gewichtung und Zusammensetzen der Ergebnislisten durch die Rankingfaktoren das Betriebsgeheimnis einer jeden Suchmaschine. Trotzdem gibt es einige bekannte und wichtige Rankingfaktoren. Jede Suchmaschine arbeitet hier verschieden – Google gibt an, über 200 Rankingfaktoren zu haben. Besonders wichtige Faktoren, die von einer Suchmaschine bei den Rankings berücksichtigt werden, sind Texte, Verlinkungen, Lokalität, Aktualität, Personalisierung, Brand, User, Vertrauen (Trust) und Technik.
- Texte: Welche Wörter in der Suchanfrage kommen im Dokument vor? Wo und in welchem Zusammenhang treten diese im Dokument auf? Synonyme, Bilder, Überschriften, Ankertexte und vieles mehr können dabei berücksichtigt werden.
- Verlinkungen (auch als die Popularität von Dokumenten bezeichnet): Wie stark wird eine Seite verlinkt und von welchen Dokumenten erhält diese Verlinkungen? Der PageRank-Algorithmus von Google misst anhand der Links die Popularität von Dokumenten.
- Lokalität: Hier wird der Standort des Suchenden berücksichtigt. Bei der Suche z. B. nach einem Zahnarzt hilft es einem User aus Düsseldorf kaum, eine Suchergebnisliste mit Zahnärzten aus Berlin angezeigt zu bekommen. Der Standort des Dokuments (Sprache, Unternehmenssitz usw.) wird bei einer Suchanfrage mit lokalem Bezug bevorzugt ausgespielt.
- Aktualität: Je nach Search Intent des Suchenden kann das Anzeigen von besonders aktuellen Dokumenten und Informationen gewünscht sein (z. B. bei Nachrichten, Wetterberichten, Sportergebnissen usw.). Da ältere Informationen meist stärker verlinkt sind, aber ggf. nicht die gewünschte Aktualität haben, können durch den Rankingfaktor „Aktualität“ Dokumente bevorzugt werden, die zwar weniger Links, dafür aber aktuellere Informationen haben.
- Personalisierung: Hierbei geht es um die persönlichen Vorlieben des Nutzers. Die Suchmaschinen passen die Suchergebnisse z. B. darauf an, welche Onlineshops der User in der Vergangenheit besonders oft angeklickt hat usw.
- Brand: Wie bekannt ist die Website bei den Usern und wie hoch ist der Brandtraffic? Eine Website, die außerhalb der Suchmaschinen bekannt ist und von den Usern als zuverlässige Quelle angesehen wird, kann durch diesen Brandeffekt auch in den Suchergebnissen besser ranken.
- User: Ein ewiger Streitpunkt sind die Daten von Usern als Rankingfaktoren. So bestreitet Google die Nutzung solcher Daten, Tests ergeben aber immer häufiger, dass Nutzerdaten, wie Klickraten in den SERPs und weiteres Nutzerverhalten, in die Rankings miteinfließen. Bing gibt zu, Nutzerdaten wie die Bouncerate und Verweildauer als Signale für die Rankings zu messen – ob Google diese ebenfalls verwendet, ist aber nicht bestätigt.
- Vertrauen: Kann der Website vertraut werden und sie dem User deshalb in den TOP 10 angezeigt werden? Googles E-E-A-T-Modell ist ein weiterer Schritt, damit die Suchmaschine, v. a. bei besonders sensiblen Themen, wie Gesundheit und Finanzen (YMYL), ausschließlich Seiten anzeigt, deren Inhalte korrekt sind und keine Gefahr für den User darstellen. EEAT ist kein direkter Rankingfaktor an sich, sondern ein Konzept der Suchmaschine, um vertrauenswürdige Seiten besser zu erkennen.
- Technik: Die Suchmaschinen müssen eine Website verstehen. Technische Hürden, wie fehlerhafte Verlinkungen, zu lange Ladezeiten, fehlerhafte Codes und viele mehr, deuten auf die schlechte Qualität einer Website hin und können es der Suchmaschine erschweren, sie zu verstehen. Nur eine technisch saubere Website kann von den Crawlern auch korrekt ausgelesen werden. Google gibt selbst an, dass bei der Optimierung die gesamte Qualität der Website beachtet werden muss und nicht nur einzelne Dokumente.
Quellen:
- http://www.bui.haw-hamburg.de/fileadmin/user_upload/lewandowski/doc/Web_Information_Retrieval_Buch.pdf
- https://de.wikipedia.org/wiki/Information_Retrieval
- http://infolab.stanford.edu/~backrub/google.html
- https://www.google.com/search/howsearchworks/
- https://www.ionos.de/digitalguide/online-marketing/suchmaschinenmarketing/information-retrieval-wie-suchmaschinen-daten-abrufen/
- https://towardsdatascience.com/text-classification-with-nlp-tf-idf-vs-word2vec-vs-bert-41ff868d1794
- https://www.enzyklopaedie-der-wirtschaftsinformatik.de/wi-enzyklopaedie/lexikon/daten-wissen/Datenmanagement/Daten-/Information-Retrieval/index.html/?searchterm=Information%20Retrieval
- https://de.wikipedia.org/wiki/Vektorraum-Retrieval
- https://de.wikipedia.org/wiki/Wahrscheinlichkeitstheorie
- https://de.wikipedia.org/wiki/Boolesches_Retrieval
- https://de.wikipedia.org/wiki/Hubs_und_Authorities
- https://www.springer.com/de/book/9783662440148
- https://www.seo-suedwest.de/6011-google-nicht-auf-das-indexieren-einzelner-urls-achten-sondern-auf-die-gesamte-qualitaet.html
- https://www.seo-suedwest.de/5942-bing-veroeffentlicht-rankingfaktoren-auch-absprungrate-und-verweildauer-zaehlen.html
- https://www.seroundtable.com/us-congress-google-uses-clicks-user-data-in-search-29870.html
Das war ein kurzer Rundumblick, wie eine Suchmaschine eigentlich arbeitet. Jeder, der seine Website optimiert, sollte immer im Hinterkopf haben, wie eine Suchmaschine funktioniert.
-Fabian
GEO-Check gefällig?
Jetzt anfragen für mehr Sichtbarkeit – in Suchmaschinen und KI-Antworten.
- Mehr Sichtbarkeit und Leads über Google und KI-Chats
- Nachhaltige SEO- & GEO-Strategien
- Persönliche Betreuung


